先輩、データの分散がなくならないっす
先輩、分散がなくならないっす。
ある研究室での先輩後輩のお話
先輩 「お、実験頑張っているね」
後輩 「先輩に統計を習ってから、誤差にも気を付けて実験してるっす。でも、どうしてもデータが分散しちゃって」
先輩 「きれいに正規分布しているんじゃない。」
後輩 「分布にきれいも汚いもあるんですか?じゃあS.D.を使って誤差を書いておけばこのデータで大丈夫ですか」
先輩 「どうしてS.D.を使うの?S.E.で良くない?」
後輩 「そうなんですか。S.D.とS.E.の使い方の違いがよくわからないっす。」
先輩 「これは統計を普段から使っている人も時々間違えているからね」
先輩の解説
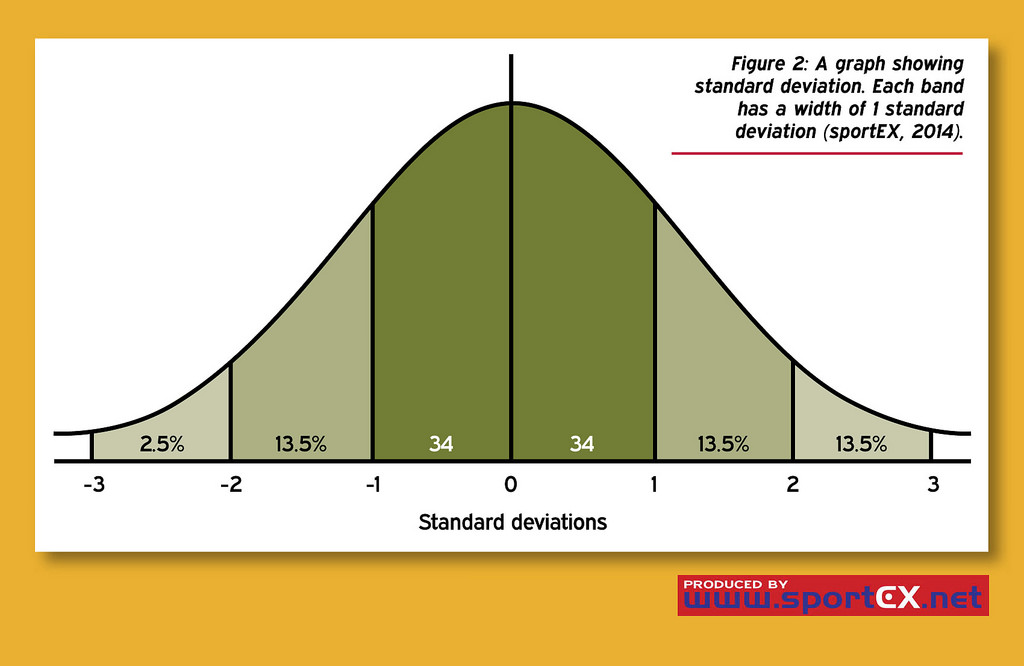
データが正規分布していれば、数学的に扱いやすい
誤差やデータの分散は避けられないもの。だから大切なのはどのようにデータが分布しているかを知ること。ランダムにばらつく自然現象や社会現象の多くは正規分布に従うんだ。実験装置の誤差も大体がそうだね。正規分布だと平均値と中央値が一致している、つまり左右対称にデータが分布しているから、数学的にはとても扱いやすいんだ。正規分布する系では、標準偏差2つ分ずれた値以内に0.95の確率で測定値が収まることが予想されることもわかっているんだ。
分散に関心があればS.D. 誤差の大きさを伝えるだけならS.E.
標準偏差S.D.と標準誤差S.E.は混同しがち。実験誤差を扱う時はSEを使うのが基本。S.E.は誤差の大きさなので測定回数を増やせば、その分小さくなっていく。一方、S.D.は誤差がなくても本来あるべきデータのばらつき。だから平均値に対してどの程度の分散があるのか、この分散そのものに興味があるときはS.D.を使うべきなんだ。
後輩「なるほど、データの分散を無くそうとするより、理解して誤差を正しく表現することが大事なんっすね。俺、ちょっと賢くなった気がします。先輩、ありがとうございました!」
参考
Excelで学ぶ統計解析入門 管 民朗 オーム社(2013)
研究者のためのわかりやすい統計学-1,-2,-3 化学と生物 51, (2013)